
Launching RAG4j/p — Learning to program a Retrieval Augmented Generation system
Frameworks like LlamaIndex, Langchain and Langchain4j make implementing your Retrieval Augmented Generation easy. The problem with these frameworks is they are so big and, therefore, hard to understand completely. What if you have a project where you can browse all the code in just an hour or so? What if you could change everything you want and experiment? That is what RAG4j and RAG4p are all about. Choose Java or Python, boot your IDE, check out the repository and start programming.
In this blog post, you read about why we started these projects. We’ll point you to the documentation, and you'll learn how to work with the framework.
If you are curious after the blog and want to learn and experiment together, join us at one of the conference workshops, the first next week at Jfokus. If you organise a conference and want this cool workshop at your conference, please get in touch with me.
Do you want to start working with the code without reading?
Basic concepts: documentation. GitHub projects: RAG4j, RAG4p
A little bit of history
I have been involved in search or information retrieval projects for over a decade. Lucene brought us the Inverted Index, and tools like Elasticsearch and Solr made it available to the enterprise. In this last decade, I helped customers improve their search on the website and helped people learn through workshops and training. A presentation I did at Luminis Devcon 2018 was titled: Will Neural Networks kill the inverted index.
This was at the time that Bert came around. Men, a lot has changed since that time. At the end of 2022, when OpenAI released ChatGPT to the public, Large Language Models started invading the information retrieval domain. It felt like the cookie jar was opened, and we were all free to eat. I wrote a lot of blogs on the topic and started using LLMs for my projects. One of the limitations of an LLM is having accurate and recent knowledge. That is when Retrieval Augmented Generation systems were created.
With RAG, you need a retriever that understands your question. Use the question to find a relevant context for you to give to the LLM to extract an answer from. With the retriever, we are back at the search domain. One thing has changed, though; everybody now uses semantic search based on vectors or embeddings. You do not need to use them, but they work well for question/answer systems.
With the experience of Luminis in search and now RAG, we started giving workshops worldwide. Ok, maybe it's an exaggeration. However, I did present at Haystack USA, Devoxx in Belgium, Jfokus in Stockholm, and on multiple occasions in the Netherlands. We learned that some people like to build RAG in Java, and others like to build in Python. We tried a workshop with Langchain and Langchain4j, but there were too many differences. Therefore, we decided to create two similar projects, small enough to learn during the workshop. Still, it is powerful enough to create an RAG system, including observability to determine its quality.
That is where we are now. We launched http://rag4j.org and http://rag4p.org.
Recap of Retrieval Augmented Generation
The next image shows an overview of what a RAG system is. It shows the application that receives a question. The application asks the retriever to create a context that must contain the answer to the question. The application calls the generator with the question and the context to ask for an answer.
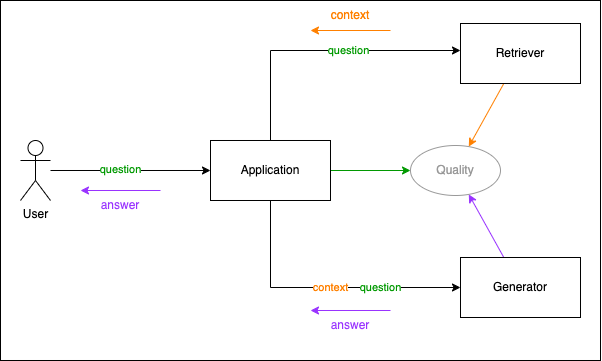
Measuring the quality of your RAG system
The quality component is responsible for determining the quality of the generated text and the retrieved chunks, all related to the question from the user. There are three metrics to determine the overall quality of your RAG:
The precision: the quality of the results of the retriever in relationship to the question. In our case, we have a judgment list with questions and the optimal chunk/result for that question. This list is created using synthetic questions generated by an LLM. From each chunk, we generate a question using an LLM. Next, the questions go through the retriever; they should return the chunk from which the question was generated. The precision is a score between 0 and 1, where one is perfect.
Contextual Accuracy: the quality of the answer in relationship to the context. The context is constructed from the chunks retrieved by the retriever. The generator generates the answer. The answer should be deduced from the context. The contextual accuracy is between 1 and 5, where five is perfect. This score is obtained through the LLM by asking the LLM about the quality of the answer concerning the context.
Answer Completeness: the quality of the answer in relationship to the question. The generator generates the answer. The answer should be deduced from the question. The answer accuracy is a score between 1 and 5, where five is perfect. The score is obtained through the LLM by asking the LLM about the quality of the answer concerning the question.
Code sample
Below are two code samples. They both use OpenAI version of the generator. They send the question and the context to the generator and receive an answer.
More code samples are available in the repository.
KeyLoader keyLoader = new KeyLoader();
AnswerGenerator answerGenerator = new OpenAIAnswerGenerator(keyLoader);
String question = "Since when was the Vasa available for the public to visit?";
String context = "By Friday 16 February 1962, the ship is ready to be displayed to the general public at the " +
"newly-constructed Wasa Shipyard, where visitors can see Vasa while a team of conservators, " +
"carpenters and other technicians work to preserve the ship.";
String answer = answerGenerator.generateAnswer(question, context);
System.out.printf("The question is: %s%n", question);
System.out.printf("The answer is: %s%n", answer);from dotenv import load_dotenv
load_dotenv()
key_loader = KeyLoader()
question = "Since when was the Vasa available for the public to visit?"
context = ("By Friday 16 February 1962, the ship is ready to be displayed to the general public at the "
"newly-constructed Wasa Shipyard, where visitors can see Vasa while a team of conservators, "
"carpenters and other technicians work to preserve the ship.")
answer_generator = OpenaiAnswerGenerator(openai_api_key=key_loader.get_openai_api_key())
answer = answer_generator.generate_answer(question, context)
print(f"Question: {question}")
print(f"Answer: {answer}")Checking out the project
I hope you are curious about the project and want to try it out. Both repositories contain a readme file that should get you going. If you spot bugs or problems, feel free to create an issue. Please get in touch with me if you have questions or remarks.
repositories
Java: https://github.com/rag4j/rag4j
Python: https://github.com/rag4j/rag4p
Documentation: https://www.rag4j.org or https://www.rag4p.org (points to the same website)
